Qu'est-ce que l'informatique de périphérie ?
L'informatique de périphérie est un modèle informatique décentralisé dans lequel le traitement des données a lieu au plus près de leur source, plutôt que d'être transmis à un centre de données centralisé ou à un environnement cloud. Cette approche contraste avec les architectures informatiques traditionnelles qui reposent fortement sur un traitement centralisé, souvent situé loin des appareils générant les données.
Dans un cadre de calcul en périphérie, l'analyse des données et la réactivité du système s'effectuent au plus près du lieu de génération des données, qu'elles proviennent de systèmes IoT, de capteurs périphériques IoT ou de systèmes de contrôle industriels. Cette approche locale du calcul permet aux systèmes de fonctionner avec une plus grande autonomie, leur permettant d'interpréter les données et d'agir en conséquence sans dépendre d'une communication constante avec un cloud ou un centre de données central.
L'informatique de périphérie est étroitement liée au concept de périphérie intelligente , où les dispositifs situés en périphérie du réseau traitent et analysent les données en temps réel, permettant une prise de décision plus rapide et plus intelligente. Ces applications relèvent souvent de l'Internet des objets (IoT) , conçu pour tirer parti du calcul localisé et ainsi améliorer la réactivité.
L'essor du edge computing reflète le besoin croissant de gérer en temps réel l'afflux massif de données générées par les dispositifs distribués. Face à la complexité et à la dispersion géographique croissantes des environnements numériques, les architectures centralisées classiques peinent souvent à répondre aux exigences de performance et d'évolutivité. Le edge computing relève ce défi en distribuant la capacité de calcul sur différents points du réseau, ce qui permet d'obtenir des informations plus rapidement et d'adopter un comportement système plus adaptatif.
Ce modèle décentralisé représente un changement fondamental dans la manière dont les organisations conçoivent et déploient les applications modernes. Au lieu de centraliser toutes les tâches de traitement, l'informatique de périphérie favorise les opérations localisées et prend en charge une infrastructure évolutive et résiliente dans tous les secteurs, de la production et la logistique à la santé et aux villes intelligentes, souvent grâce à des systèmes intermédiaires comme les passerelles IoT pour connecter les dispositifs périphériques aux réseaux plus vastes.
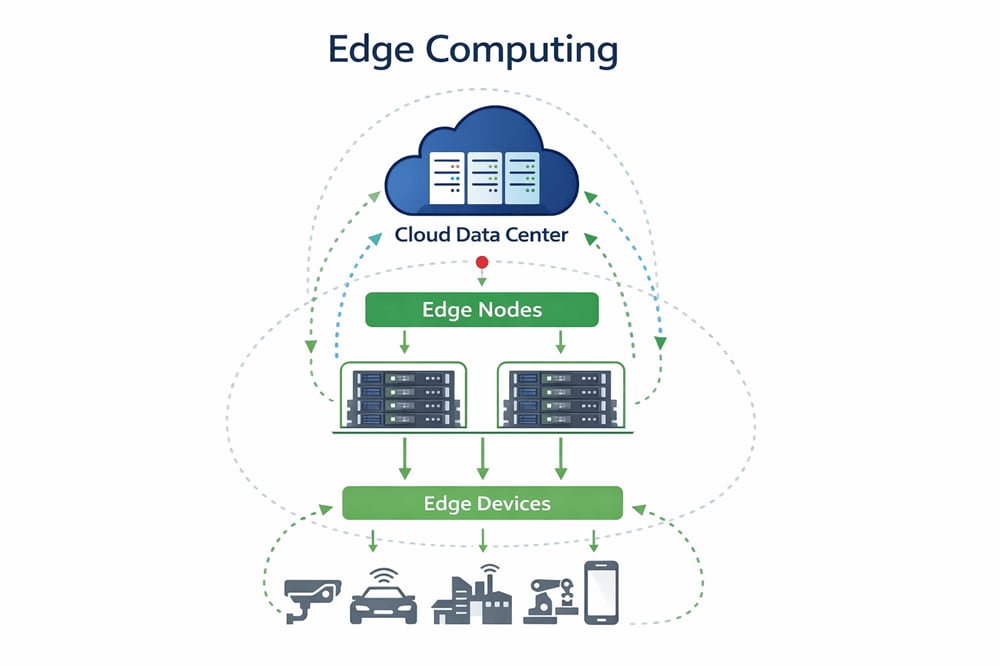
Comment fonctionne l'informatique de périphérie
L'informatique de périphérie (ou edge computing) consiste à délocaliser les tâches de calcul essentielles, telles que l'analyse et le traitement des données, des centres de données centralisés vers des sites distribués, physiquement plus proches du lieu de génération des données. Ce changement ne se limite pas à une simple question de géographie ; il implique une restructuration de l'architecture afin de prendre en charge les opérations critiques en temps réel, de réduire la dépendance au réseau et de permettre une prise de décision en temps réel à la source. Les environnements de périphérie sont généralement constitués d'un système en couches comprenant des dispositifs de périphérie, des nœuds de calcul localisés et des composants réseau qui se coordonnent avec les systèmes centraux selon les besoins.
Les serveurs embarqués de pointe jouent un rôle crucial dans le domaine de l'informatique de périphérie. Conçus pour être économes en énergie tout en offrant des performances robustes, ils répondent aux exigences élevées des tâches d'informatique de périphérie. S'inscrivant dans une démarche d'informatique verte , ces solutions visent à minimiser leur impact environnemental. Elles y parviennent en réduisant leur empreinte carbone tout en optimisant leur efficacité opérationnelle.
De même, ces solutions serveur sont conçues pour fonctionner de manière fiable dans des conditions environnementales difficiles. Elles garantissent ainsi des performances constantes dans divers environnements, y compris ceux présentant des températures extrêmes ou d'autres exigences opérationnelles élevées. Leur polyvalence et leur robustesse les rendent idéales pour une large gamme d'applications de calcul en périphérie.
Les systèmes de périphérie sont généralement conçus avec une sécurité renforcée, car ils traitent souvent des données sensibles en dehors des périmètres informatiques traditionnels. Les contrôles de sécurité localisés, le chiffrement et le renforcement du système sont essentiels pour garantir l'intégrité et la confidentialité des données traitées en périphérie.
En déployant la puissance de calcul au plus près du lieu de production des données, l'informatique de périphérie permet des temps de traitement plus rapides, réduit la pression sur la bande passante du réseau et améliore la réactivité des services et appareils numériques.
Informatique de périphérie vs. informatique en nuage vs. informatique de brouillard
Bien que l'informatique de périphérie, le cloud et le fog computing soient tous liés à la manière et au lieu où les données sont traitées, chacun représente une approche distincte de l'architecture informatique, avec des applications et des caractéristiques de performance différentes.
L'informatique en nuage repose sur des centres de données centralisés, souvent situés loin du lieu de production des données. Dans ce modèle, les données sont transmises via un réseau (généralement Internet) pour être traitées, stockées et gérées par des fournisseurs de services cloud. Cette approche offre évolutivité et contrôle centralisé, mais peut engendrer des limitations de latence et de bande passante, notamment pour les applications en temps réel ou à fort volume de données.
À l'inverse, le edge computing traite les données localement ou à proximité de leur source. Ce modèle réduit la distance parcourue par les données et minimise la latence en analysant les informations directement sur l'appareil ou sur un nœud edge proche. Il est parfaitement adapté aux cas d'usage nécessitant des informations ou une action immédiates, tels que les systèmes autonomes, l'automatisation industrielle ou l'analyse vidéo sur site.
Le fog computing sert d'intermédiaire entre les environnements edge et cloud. Il étend les capacités du cloud au plus près de la périphérie en introduisant une couche de calcul distribué qui opère entre les dispositifs locaux et l'infrastructure cloud centralisée. Le fog computing permet de gérer les tâches trop gourmandes en ressources pour les dispositifs edge, mais trop sensibles à la latence pour un traitement exclusivement cloud.
En résumé, le cloud computing est centralisé, l'edge computing est entièrement décentralisé et le fog computing propose une approche hybride. Chaque modèle a son utilité selon les besoins spécifiques en matière de vitesse, de bande passante, de souveraineté des données et de puissance de traitement.
Principaux avantages du Edge Computing
L'informatique de périphérie offre plusieurs avantages stratégiques et opérationnels qui en font une architecture attrayante pour les applications modernes gourmandes en données.
L'un des principaux avantages est la réduction de la latence. En traitant les données directement à la source ou à proximité, l'informatique de périphérie élimine la nécessité de transmettre les informations sur de longues distances vers des systèmes centralisés. Cela raccourcit considérablement les temps de réponse, ce qui est essentiel pour les applications en temps réel telles que les véhicules autonomes, la réalité augmentée, l'automatisation industrielle et le diagnostic à distance en télémédecine.
Un autre avantage clé réside dans l'efficacité de la bande passante. Le traitement localisé des données permet aux systèmes de filtrer, d'analyser et d'exploiter les données avant de ne transmettre que les informations essentielles aux plateformes cloud centralisées. Cela minimise le volume de données transitant sur le réseau, réduisant ainsi la consommation de bande passante et les coûts associés, un atout particulièrement précieux dans les environnements où la connectivité est limitée ou onéreuse.
L'informatique de périphérie offre une sécurité et une confidentialité des données renforcées. Le traitement des données sur site ou au sein de l'infrastructure locale réduit l'exposition des informations sensibles lors de leur transmission. Cela permet de diminuer le risque d'interception ou d'accès non autorisé, notamment dans les secteurs soumis à des réglementations strictes, tels que la santé, la finance et les infrastructures critiques.
Enfin, l'informatique de périphérie contribue à une plus grande fiabilité du système. Les dispositifs et nœuds de périphérie pouvant fonctionner indépendamment du cloud central, ils peuvent continuer à fonctionner en cas de perturbations ou de pannes de réseau. Cette résilience localisée garantit la continuité de service, même lorsque la connectivité à l'infrastructure centrale est temporairement perdue.
Ces avantages combinés font de l'informatique de périphérie une approche puissante pour les organisations qui cherchent à améliorer leurs performances, à réduire les risques opérationnels et à mieux prendre en charge les environnements distribués.
Cas d'utilisation et applications
L'informatique de périphérie permet un traitement sur site ou à proximité, devenu essentiel pour les secteurs exigeant une prise de décision rapide et un contrôle localisé. Sa capacité à rapprocher la puissance de calcul de la source de génération des données a ouvert de nouvelles perspectives d'innovation, notamment dans les environnements où la latence, la fiabilité et la réactivité sont critiques.
Dans le secteur manufacturier, l'informatique de périphérie permet la maintenance prédictive, le contrôle qualité en temps réel et l'optimisation de la production grâce à l'analyse des données des capteurs directement sur la chaîne de production. Les systèmes de santé exploitent les capacités de l'informatique de périphérie pour faciliter les diagnostics à distance, la surveillance des patients et l'imagerie médicale dans des environnements où une faible latence est essentielle. Dans le commerce de détail, l'infrastructure de périphérie prend en charge les systèmes de caisse intelligents, les expériences client personnalisées et la gestion efficace des stocks grâce au traitement local des données en magasin.
Les véhicules autonomes s'appuient fortement sur l'informatique de périphérie pour interpréter les données des capteurs, prendre des décisions de conduite et communiquer avec les infrastructures environnantes. Tout cela se déroule en temps réel et sans nécessiter une connexion permanente au cloud. De même, les initiatives de villes intelligentes utilisent les technologies de périphérie pour gérer le trafic, surveiller les infrastructures de sécurité publique et optimiser la consommation d'énergie à l'échelle locale.
L'informatique de périphérie est étroitement liée au développement des solutions IoT de périphérie , qui consistent à traiter des données sur ou à proximité des appareils connectés. Bien que ces applications soient diverses et en pleine expansion, leurs spécificités techniques sont détaillées dans un glossaire dédié à l'informatique de périphérie IoT.
En tant que composante essentielle du calcul distribué , l'architecture de périphérie permet aux organisations d'étendre leurs capacités informatiques au monde physique, favorisant ainsi une prise de décision plus rapide, des systèmes plus résilients et des modèles de déploiement évolutifs. De l'automatisation industrielle à la santé connectée en passant par les systèmes de transport intelligents, le calcul de périphérie joue un rôle crucial dans la construction d'écosystèmes numériques rapides, efficaces et adaptables au sein des entreprises modernes.
Défis et considérations
Si l'informatique de périphérie offre des avantages indéniables en termes de vitesse, d'évolutivité et d'efficacité, elle introduit également un ensemble de défis uniques que les organisations doivent relever pour garantir un déploiement et un fonctionnement réussis.
L'une des principales préoccupations est la complexité de la gestion. Avec des ressources informatiques réparties sur plusieurs sites périphériques, le maintien de performances, d'une sécurité et de normes de configuration homogènes peut devenir de plus en plus difficile. C'est particulièrement vrai si ces ressources sont situées dans des environnements distants ou physiquement contraints. Pour y remédier, les équipes informatiques doivent gérer un large éventail de composants matériels, logiciels et réseau répartis sur des sites décentralisés.
La sécurité et la protection des données sont également des enjeux cruciaux. Bien que le traitement local des données puisse réduire leur exposition lors de la transmission, les périphériques et nœuds périphériques peuvent être plus accessibles physiquement ou fonctionner en dehors des périmètres de sécurité traditionnels des entreprises. Cela renforce la nécessité d'une protection robuste des terminaux, de processus de démarrage sécurisés et d'une surveillance en temps réel afin de se prémunir contre tout accès non autorisé ou toute altération.
L'interopérabilité et la normalisation constituent un autre défi. Les environnements périphériques impliquent souvent une grande variété d'appareils, de plateformes et de protocoles. Garantir la compatibilité entre ces composants, notamment dans les environnements multi-fournisseurs ou existants, peut impacter les efforts d'intégration et l'évolutivité à long terme.
De plus, les coûts d'infrastructure peuvent être considérables. Si l'informatique de périphérie allège la charge des centres de données centralisés, le déploiement et la maintenance de matériel de périphérie à grande échelle nécessitent des investissements dans des systèmes robustes, des sources d'alimentation fiables et une connectivité sécurisée. Le retour sur investissement dépend fortement du cas d'usage, de l'échelle du déploiement et de la stratégie opérationnelle.
Enfin, les organisations doivent prendre en compte le cycle de vie des données en périphérie. Les décisions relatives aux données à traiter localement, à celles à supprimer et à celles à envoyer vers le cloud pour un stockage à long terme ou une analyse nécessitent une planification rigoureuse et l'application de politiques strictes afin d'équilibrer les performances avec les exigences réglementaires et commerciales.
Termes clés de l'informatique de périphérie
Comprendre les composantes essentielles du edge computing est fondamental pour saisir le fonctionnement des architectures distribuées. Voici quelques termes importants couramment associés aux environnements edge :
Nœud périphérique
Un nœud périphérique est un point de terminaison informatique localisé qui traite ou relaie les données générées par les appareils à proximité. Il constitue généralement la première couche de traitement dans la hiérarchie du calcul en périphérie, permettant le filtrage des données en temps réel ou la prise de décision au plus près de la source.
Porte
Une passerelle sert d'intermédiaire entre les périphériques et les réseaux ou systèmes centraux. Elle gère le trafic de données, assure la traduction des protocoles et effectue souvent des traitements de base ou des tâches de sécurité avant de transmettre les données en amont ou en aval.
Micro centre de données
Les micro-centres de données sont des installations compactes et autonomes qui fournissent des ressources de calcul, de stockage et de réseau au plus près du lieu d'utilisation. Ils prennent en charge des applications spécifiques ou des charges de travail localisées, réduisant ainsi la nécessité d'envoyer des données vers des centres de données distants.
Dispositif Edge
Un dispositif périphérique est un terminal, tel qu'un capteur, une caméra ou un contrôleur industriel, qui génère ou consomme des données au sein d'un environnement informatique périphérique. Ces dispositifs disposent souvent d'une capacité de traitement limitée permettant des réponses en temps réel.
Edge Orchestrator
Un orchestrateur de périphérie est une couche logicielle ou une plateforme qui gère, déploie et supervise les charges de travail sur plusieurs nœuds périphériques. Il permet un contrôle centralisé d'une infrastructure décentralisée, contribuant ainsi à garantir la cohérence et l'évolutivité.
Latence
En informatique de périphérie, la latence désigne le délai entre la génération des données et leur traitement. Réduire la latence est l'un des principaux objectifs du rapprochement des ressources de calcul de la source de données.
Traitement en temps réel
Ce terme désigne la capacité d'un système à ingérer, analyser et traiter des données en quelques millisecondes. L'informatique de périphérie (Edge Computing) permet un traitement en temps réel en minimisant les délais de transmission et en autorisant un calcul local immédiat.
FAQ
- Quelle est la différence entre l'informatique de périphérie et l'informatique en nuage ?
Bien que l'informatique de périphérie et l'informatique en nuage impliquent toutes deux le stockage et le traitement des données, la principale différence réside dans leur localisation. L'informatique en nuage centralise le traitement dans de grands centres de données, souvent situés loin des utilisateurs finaux. À l'inverse, l'informatique de périphérie traite les données au plus près de leur lieu de production. - Comment l'informatique de périphérie améliore-t-elle l'IoT ?
L'informatique de périphérie complète l'Internet des objets en permettant aux appareils de traiter et d'analyser les données localement, plutôt que de les envoyer vers un cloud centralisé. Il en résulte une prise de décision plus rapide, un atout majeur pour les applications critiques en temps réel telles que l'automatisation industrielle, les villes intelligentes ou les systèmes autonomes. - L'informatique de périphérie est-elle plus sécurisée que l'informatique en nuage ?
L'informatique de périphérie peut améliorer la confidentialité et la sécurité des données en limitant la distance parcourue par les données sensibles, réduisant ainsi leur exposition lors de la transmission. Cependant, elle soulève également de nouveaux défis en matière de sécurité, comme la gestion d'un grand nombre de terminaux distribués. Les environnements de périphérie et de cloud nécessitent tous deux des stratégies de sécurité complètes et adaptées au contexte. - Pourquoi l'informatique de périphérie est-elle importante pour la 5G ?
L'informatique de périphérie est essentielle aux réseaux 5G car elle contribue à réduire la latence. La 5G permettant une transmission de données plus rapide, l'infrastructure de périphérie garantit que le traitement puisse suivre le rythme, notamment pour les applications mobiles et gourmandes en bande passante. - Quels sont des exemples concrets d'informatique de périphérie ?
Parmi les exemples concrets d'informatique de périphérie, citons les véhicules autonomes qui traitent les données de leurs capteurs en temps réel, les commerces de détail qui utilisent l'analyse du comportement des clients en magasin et les installations industrielles qui déploient des systèmes de maintenance prédictive sur leurs chaînes de production. Ces scénarios nécessitent un traitement immédiat des données, sans dépendre de centres de données distants.