4U/8U AI Training Servers with Habana Gaudi AI Processors and SynapseAI Software
Demand for high-performance AI/Deep Learning (DL) training compute has doubled in size every 3.5 months since 2013 (according to OpenAI) and is accelerating with the growing size of data sets and the number of applications and services based on computer vision, natural language processing, recommendation systems, and more. With the increased demand for greater training performance, throughput, and capacity, the industry needs training systems that offer increased efficiency, lower cost, ease of implementation, flexibility to enable customization, and scaling of training systems. AI has become an essential technology for diverse areas such as virtual assistants, manufacturing operations, autonomous vehicle operations, and medical imaging, to name a few. Supermicro has partnered with Habana Labs to address these growing requirements.

Supermicro X12 Gaudi AI Training System: SYS-420GH-TNGR
The Supermicro X12 Gaudi AI Training System prioritizes two key real-world considerations: training AI models as fast as possible, while simultaneously reducing the cost of training. It features eight Gaudi HL-205 mezzanine cards, dual 3rd Gen Intel® Xeon® Scalable processors, two PCIe Gen 4 switches, four hot swappable NVMe/SATA hybrid hard drives, fully redundant power supplies, and 24 x 100GbE RDMA (6 QSFP-DDs) for unprecedented scale-out system bandwidth. This system contains up to 8TB of DDR4-3200MHz memory, unlocking the Gaudi AI processors' full potential. The HL-205 is OCP-OAM (Open Compute Project Accelerator Module) specification compliant. Each card incorporates a Gaudi HL-2000 processor with 32GB HBM2 memory and ten natively integrated ports of 100GbE RoCE v2 RDMA.
The system enables high-efficiency AI model training for a wide array of applications:
Computer vision applications:
- Manufacturing defect detection, resulting in better products with fewer warranty issues
- Fraud detection, saving billions of dollars annually
- Inventory management, allowing enterprises to become more efficient
- Medical imaging to detect abnormalities
- Identification of photos and videos to enhance security.
Language applications:
- Question answering
- Subject matter queries
- Chatbots and translations
- Sentiment analysis for recommendation systems

Coming soon – Supermicro Gaudi®2 AI Training Server: SYS-820GH-TNR2
The Supermicro Gaudi2 AI Training Server prioritizes two key real-world considerations: integrating multi AI training system to analyze diverse AI models faster, while simultaneously multiple scalability function and price advantages. It features eight Gaudi2 HL-225H mezzanine cards, dual 3rd Gen Intel® Xeon® Scalable processors, two PCIe Gen 4 switches, 24 hot swappable hard drives (SATA/NVMe/SAS), fully redundant power supplies, and 24 x 100GbE (48 x 56Gb) PAM4 SerDes Links by6 QSFP-DDs for unprecedented scale-out system bandwidth. This system contains up to 8TB of DDR4-3200MHz memory, unlocking the Gaudi2 AI processors' full potential. The HL-225H is OCP-OAM v1.1(Open Compute Project Accelerator Module) specification compliant. Each card incorporates a Gaudi2 processor with 96GB HBM2E memory and 8 x 3 x 100Gb = 2.4 Tb total scale-out by 6 QSFP-DD.
| Habana Gaudi AI Training System Specifications | X12 Gaudi AI Training Server | Gaudi2 AI Training Server |
|---|---|---|
| Processor Support | Dual 3rd Gen Intel® Xeon® Scalable processors, Socket P+ (LGA-4189), up to 270W TDP | |
| Serverboard | X12DPG-U6 | X12DPG-OA6-GD2 |
| System Memory | 32x DIMM slots, 3200/2933/2666MHz ECC DDR4 RDIMM/LRDIM | |
| AI Processors | 8x Habana Gaudi AI processors on OAM mezzanine cards, 350W TDP, passive heatsinks | 8x Habana Gaudi2 AI processors on OAM mezzanine cards, 600W TDP, passive heatsinks |
| Expansion Slots | Dual x16 PCI-E AIOM (SFF OCP 3.0 superset) plus single x16 PCI-E 4.0 full height, half-length expansion slot | 3 PCI-E Slots: 2x PCI-E 4.0 x8 (FHHL) & 1x PCI-E 4.0 x16 (FHHL). Optional 4x PCI-E 4.0 x8 (LP) or 2x PCI-E 4.0 x16 (LP) |
| Connectivity | 1x 10GbE dedicated IPMI LAN via RJ45, 6x 400Gb QSFP-DD ports, 2x USB 3.0 | |
| VGA/Audio | VGA via BMC | |
| Drive Bays | 4x internal 2.5" hot-swap NVMe/SATA/SAS Drive Bays. | 24x internal 2.5" hot-swap NVMe/SATA/SAS Drive Bays |
| Storage | 2x M.2 NVMe OR 2x M.2 SATA3 | 2x M.2 PCIe 3.0 x4 slots |
| Power Supply | 4x 3000W redundant power supplies, 80+ Titanium level Tested power draw: 4922W* | 6x 3000W High efficiency (54V+12V) |
| Cooling System | 5x removable heavy-duty fans | 12x removal heavy-duty fans |
| Operating Temperature | 10°C ~ 35°C (50°F ~ 95°F) | |
| Form Factor | 178 x 447 x 813mm (7" x 17.6" x 32") | 447 x 356 x 800mm (17.6" x 14" x 31.5) |
| Weight | Gross weight: 137lbs (62kg) | TBD |
| * Tested configuration: | ||
More hardware details for SYS-420GH-TNGR are available on the product spec page.
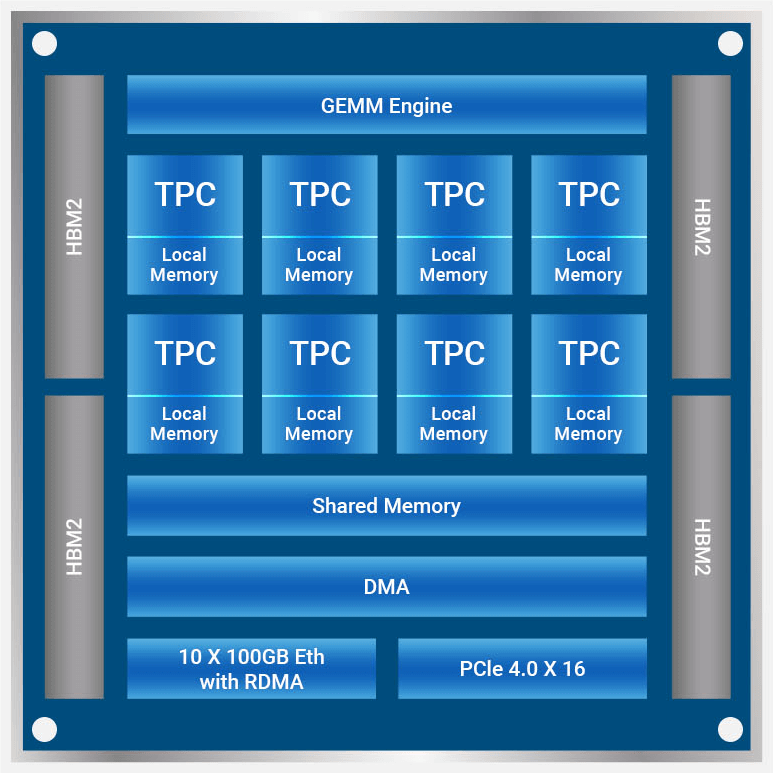
Habana Gaudi AI Processor
The Habana® Gaudi® AI processor is designed to maximize price-performance, ease of use and scalability. Training on Gaudi AI processors provides:
Gaudi Training Efficiency
Architected to optimize AI performance, Gaudi delivers higher efficiency than traditional processor architectures:
- Heterogeneous compute architecture to maximize training efficiency
- Eight fully programmable, AI-customized Tensor Processor Cores
- Configurable centralized GEMM engine (matrix multiplication engine)
- Software managed memory architecture with 32 GB of HBM2 memory
Habana Gaudi2 AI Processor
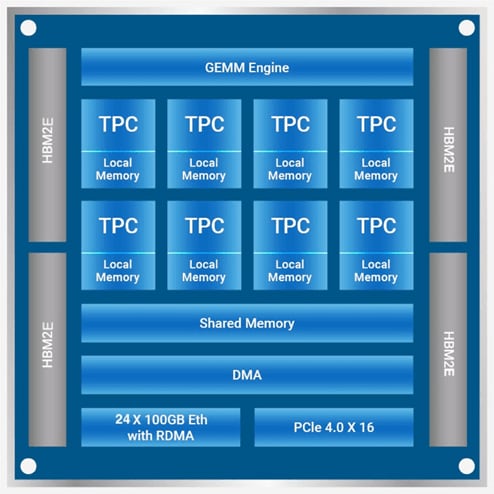
The Habana® Gaudi®2 AI processor is designed to maximize price-performance, ease of use and scalability. Training on Gaudi AI processors provides:
Gaudi2 Training Efficiency
Architected to optimize AI performance, Gaudi2 delivers higher efficiency than traditional processor architectures:
- Heterogeneous compute architecture to maximize training efficiency
- Eight fully programmable, AI-customized Tensor Processor Cores
- Configurable centralized GEMM engine (matrix multiplication engine)
- Software managed memory architecture with 96 GB of HBM2E memory
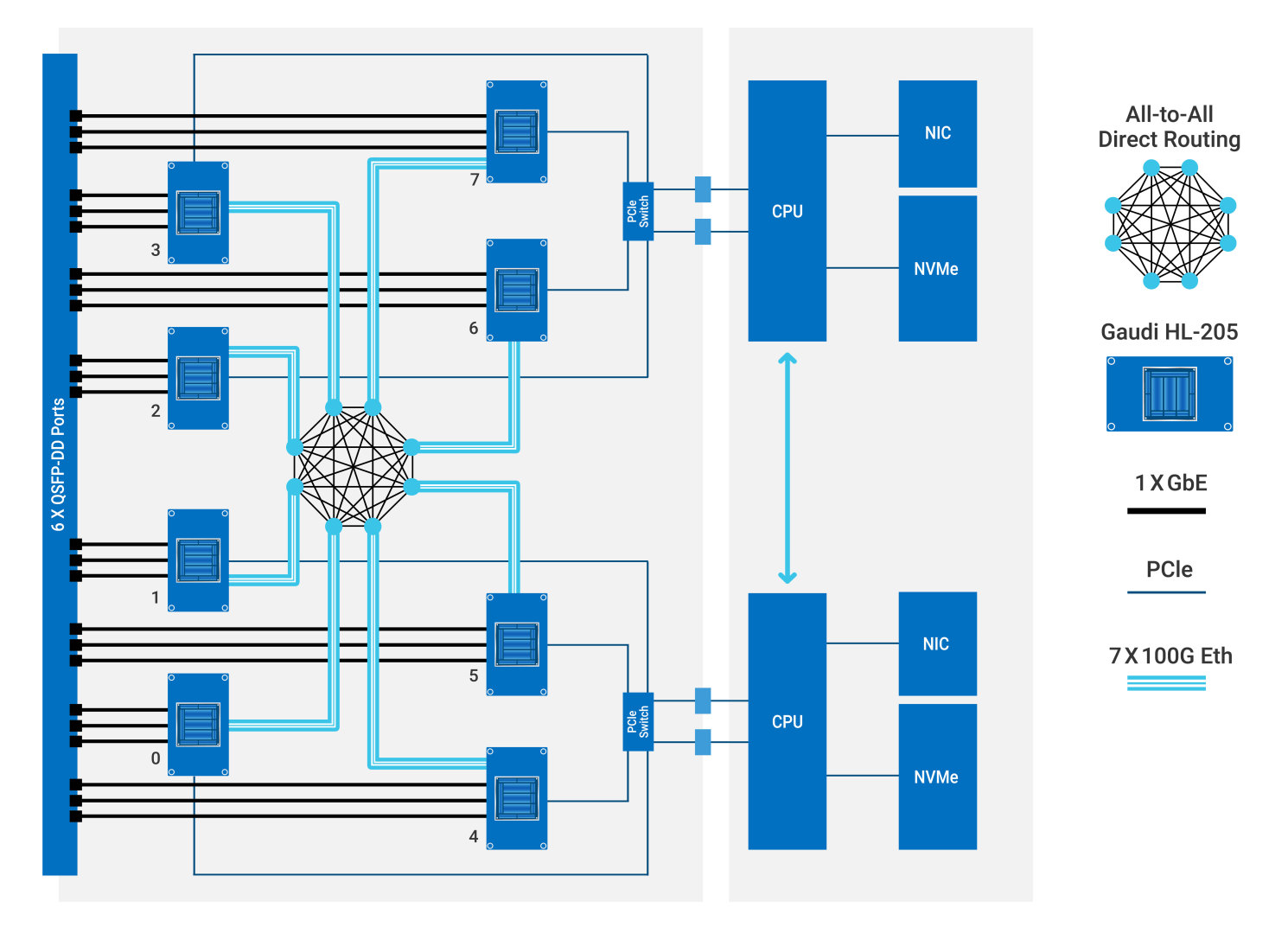
Gaudi Scaling Efficiency
Native integration of 10 x 100 Gigabit Ethernet RoCE ports onto every Gaudi AI processor
- Eliminates network bottlenecks
- Standard Ethernet inside the server and across nodes can scale from one to thousands of Gaudi processors
- Lowers total system cost and power by reducing discrete components
Each of the Gaudi AI processors dedicates seven of its ten 100GbE RoCE ports to an all-to-all connectivity within the system, with three ports available for scaling out for a total of 24 x100GbE RoCE ports per 8-card system. This allows end customers to scale their deployment using standard 100GbE switches, thus achieving overall system cost advantages. The high throughput of RoCE bandwidth inside and outside the box and the unified standard protocol used for scale-out make the solution easily scalable and cost-effective. This diagram shows a system with eight Gaudi HL-205 processors and the communication paths between the AI processors and the server CPUs.
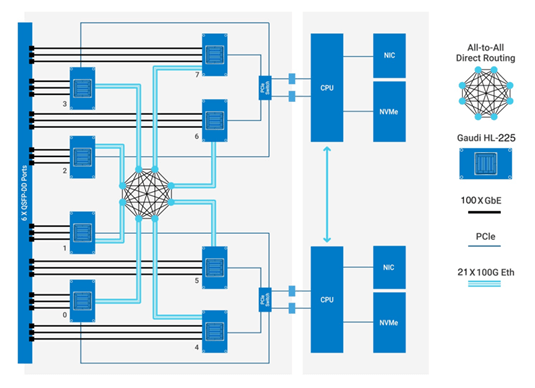
Gaudi2 Scaling Efficiency
Native integration of 24 x 100 Gigabit Ethernet RoCE ports onto every Gaudi2 AI processor
- Eliminates network bottlenecks
- Standard Ethernet inside the server and across nodes can scale from one to thousands of Gaudi2 processors
- Lowers total system cost and power by reducing discrete components
Each of the Gaudi2 AI processors dedicates 21 of its 24 100GbE RoCE ports to an all-to-all connectivity within the system, with three ports available for scaling out for a total of 24 x100GbE RoCE ports per 8-card system. This allows end customers to scale their deployment using standard 100/400GbE switches, thus achieving overall system cost advantages. The high throughput of RoCE bandwidth inside and outside the box and the unified standard protocol used for scale-out make the solution easily scalable and cost-effective. This diagram shows a system with eight Gaudi HL-225H processors and the communication paths between the AI processors and the server CPUs.
Plug-and-Play AI Training Cluster Solution:
Gaudi’s integration of compute and networking functionality enables easy and near-linear scaling of Gaudi systems from one to thousands. Supermicro supports full AI data center clusters including AI inferencing (leveraging Habana Goya inference processors), CPU node and storage servers, networking systems, and complete rack solutions. As an early implementation example, the Supermicro X12 AI Training server is being deployed in the San Diego Supercomputing Center on the University of California, San Diego campus build of the Voyager supercomputer, with its 42-node scale-out.

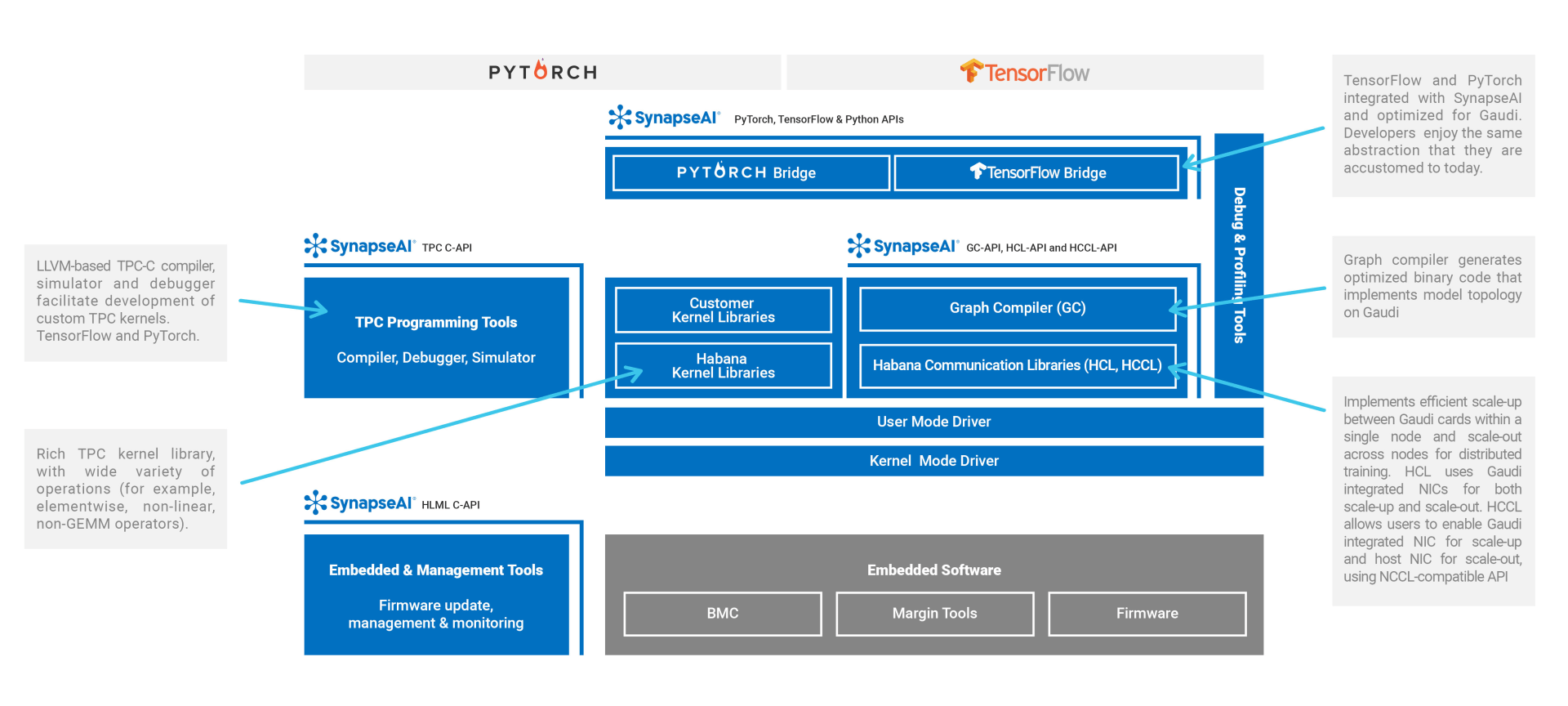
SynapseAI Software Stack for Gaudi Systems:
The SynapseAI® software stack is optimized for the Gaudi hardware architecture and designed for ease of Gaudi use. It was created with the needs of developers and data scientists in mind, providing versatility and ease of programming to address end-users’ unique needs, while allowing for simple and seamless building of new models and porting of existing models to Gaudi. SynapseAI software facilitates developers’ ability to customize Gaudi systems, enabling them to address their specific requirements and create their own custom innovations.
Features of the SynapseAI stack:
- Integrated TensorFlow and PyTorch frameworks
- Support for popular computer vision, NLP and recommendation models
- TPC programming tools: compiler, debugger and simulator
- Extensive Habana kernel library and library for Customer Kernel development
- Habana Communication Libraries (HCL and HCCL)
Habana Gaudi Solution Brief:

For more information about AI Training solutions from Supermicro:
For the latest information on Habana Gaudi, see Habana® AI Training
Developers and IT and systems administrators can visit Habana’s Developer Site