
NVIDIA GB300 NVL72
Liquid Cooled Rack-Scale Solution with 72 NVIDIA B300 GPUs and 36 Grace CPUs
- GPU: 72 NVIDIA B300 GPUs via NVIDIA Grace Blackwell Superchips
- CPU: 36 NVIDIA Grace CPUs via NVIDIA Grace Blackwell Superchips
- Memory: Up to 21 TB HBM3e (GPU Memory), Up to 17 TB LPDDR5X (System Memory)
- Drives: up to 144 E1.S PCIe 5.0 drive bays

Liquid-Cooled Universal GPU Systems
Direct-to-chip liquid-cooled systems for high-density AI infrastructure at scale.
- GPU: NVIDIA HGX B300/B200/H200
- CPU: Intel® Xeon® or AMD EPYC™
- Memory: Up to 32 DIMMs, 9TB
- Drives: Up to 24 Hot-swap U.2 or 2.5" NVMe/SATA drives

Universal GPU Systems
Modular Building Block Design, Future Proof Open-Standards Based Platform in 4U, 5U, 8U, or 10U for Large Scale AI training and HPC Applications
- GPU: NVIDIA HGX B300/B200/H200, AMD Instinct MI350 Series and MI325X/MI300X/MI250 OAM Accelerator, Intel Data Center GPU Max Series
- CPU: Intel® Xeon® or AMD EPYC™
- Memory: Up to 32 DIMMs, 9TB
- Drives: Up to 24 Hot-swap E1.S, U.2 or 2.5" NVMe/SATA drives

3U/4U/5U GPU Lines with PCIe 5.0
Maximum Acceleration and Flexibility for AI, Deep Learning and HPC Applications
- GPU: Up to 10 NVIDIA H100 PCIe GPUs, or up to 10 double-width PCIe GPUs
- CPU: Intel® Xeon® or AMD EPYC™
- Memory: Up to 32 DIMMs, 9TB or 12TB
- Drives: Up to 24 Hot-swap 2.5" SATA/SAS/NVMe

NVIDIA MGX™ Systems
Modular Building Block Platform Supporting Today's and Future GPUs, CPUs, and DPUs
- GPU: Up to 4 NVIDIA PCIe GPUs including NVIDIA RTX PRO™ 6000 Blackwell Server Edition, H200 NVL, H100 NVL, and L40S
- CPU: NVIDIA GH200 Grace Hopper™ Superchip, Grace™ CPU Superchip, or Intel® Xeon®
- Memory: Up to 960GB ingegrated LPDDR5X memory (Grace Hopper or Grace CPU Superchip) or 16 DIMMs, up to 4TB DRAM (Intel)
- Drives: Up to 8 E1.S + 4 M.2 drives

AMD APU Systems
Multi-processor system combining CPU and GPU, Designed for the Convergence of AI and HPC
- GPU: 4 AMD Instinct MI300A Accelerated Processing Unit (APU)
- CPU: AMD Instinct™ MI300A Accelerated Processing Unit (APU)
- Memory: Up to 512GB integrated HBM3 memory (4x 128GB)
- Drives: Up to 8 2.5" NVMe or Optional 24 2.5" SATA/SAS via storage add-on card + 2 M.2 drives

4U GPU Lines with PCIe 4.0
Flexible Design for AI and Graphically Intensive Workloads, Supporting Up to 10 GPUs
- GPU: NVIDIA HGX A100 8-GPU with NVLink, or up to 10 double-width PCIe GPUs
- CPU: Intel® Xeon® or AMD EPYC™
- Memory: Up to 32 DIMMs, 8TB DRAM or 12TB DRAM + PMem
- Drives: Up to 24 Hot-swap 2.5" SATA/SAS/NVMe

2U 2-Node Multi-GPU with PCIe 4.0
Dense and Resource-saving Multi-GPU Architecture for Cloud-Scale Data Center Applications
- GPU: Up to 3 double-width PCIe GPUs per node
- CPU: Intel® Xeon® or AMD EPYC™
- Memory: Up to 8 DIMMs, 2TB per node
- Drives: Up to 2 front hot-swap 2.5” U.2 per node

GPU Workstation
Flexible Solution for AI/Deep Learning Practitioners and High-end Graphics Professionals
- GPU: Up to 4 double-width PCIe GPUs
- CPU: Intel® Xeon®
- Memory: Up to 16 DIMMs, 6TB
- Drives: Up to 8 hot-swap 2.5” SATA/NVMe
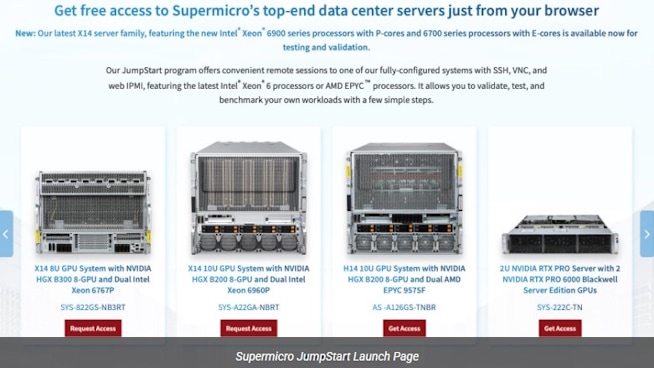
Supermicro JumpStart Testbericht: Eine Woche mit einer NVIDIA HGX B200
Supermicro 'S JumpStart Das Programm verfolgt einen ganz anderen Ansatz bei der Hardwarebewertung. Anstelle einer kurzen, skriptbasierten Demo in einer gemeinsam genutzten Laborumgebung, JumpStart Bietet qualifizierten Kunden kostenlosen, zeitlich begrenzten Bare-Metal-Zugriff auf einen Katalog realer Produktionsserver.

Sicherung KI Workloads mit Intel® TDX, NVIDIA Confidential Computing und Supermicro Server mit NVIDIA HGX™ B200 GPUs: Eine Grundlage für Vertraulichkeit KI im Maßstab
Lesen Sie das Weißbuch
Sakura Internet Koukaryoku Cloud Services Accelerate KI Dienstleistungen
Lesen Sie die Erfolgsgeschichte
Supermicro SYS-821GE-TNHR 8x NVIDIA H200 GPU Luftgekühlt KI Server
Heute setzen wir unsere Betrachtung von Massiven fort. KI Server mit Blick auf die Supermicro SYS-821GE-TNHR. Wenn Leute darüber sprechen Supermicro 'S KI Serverleistung – dieses System unterscheidet sich auf dem Markt durch seine Luftkühlung von anderen NVIDIA-Servern.

Supermicro mit GAUDI 3 KI Bietet skalierbare Leistung für KI Anforderungen
Lesen Sie das Weißbuch
Supermicro und Intel GAUDI 3 Systems Advance Enterprise KI Infrastruktur
Lesen Sie die Produktbeschreibung.
Lamini wählt Supermicro GPU-Server für LLM-Tuning-Angebot
Lesen Sie die Erfolgsgeschichte
Supermicro Das Grace-System bietet die 4-fache Leistung für ANSYS® LS-DYNA®.
Lesen Sie die Lösungsübersicht
Applied Digital baut Massive KI Wolke mit Supermicro GPU-Server
Lesen Sie die Erfolgsgeschichte
Supermicro 4U AMD EPYC GPU-Serverangebot KI Flexibilität (AS-4125GS-TNRT)
Supermicro bietet schon lange GPU-Server in so vielen verschiedenen Ausführungen und Größen an, dass wir sie in diesem Testbericht nicht alle behandeln können. Heute sehen wir uns den relativ neuen, luftgekühlten 4U-GPU-Server an, der zwei GPUs unterstützt. AMD EPYC CPUs der Serie 9004, PCIe Gen5 und wahlweise acht doppelt breite oder zwölf einfach breite Zusatz-GPU-Karten.

Supermicro Und Nvidia entwickelt Lösungen zur Beschleunigung von CFD-Simulationen für die Automobil- und Luftfahrtindustrie.
Lesen Sie die Lösungsübersicht
Ein Blick auf die Flüssigkeitskühlung Supermicro SYS-821GE-TNHR 8x NVIDIA H100 KI Server
Heute wollten wir uns die flüssigkeitsgekühlten Supermicro SYS-821GE-TNHR-Server. Dies ist Supermicro Das System mit 8 NVIDIA H100-Grafikkarten hat eine Besonderheit: Es ist flüssigkeitsgekühlt, was die Kühlkosten und den Stromverbrauch senkt. Da wir die Fotos hatten, dachten wir, wir könnten daraus einen Artikel machen.

Zugriffsmöglichkeiten PCIe GPUs in einer Hochleistungsserverarchitektur
Lesen Sie die Produktbeschreibung.
Petrobras übernimmt Supermicro Von Atos integrierte Server zur Kostenreduzierung und Erhöhung der Explorationsgenauigkeit
Lesen Sie die Erfolgsgeschichte
Supermicro Und ProphetStor maximiert die GPU-Effizienz für Multitenant-LLM-Training
Lesen Sie die Lösungsübersicht
Supermicro SEEWEB erweitert sein GPU-Angebot auf mehrere Server und liefert anspruchsvollen Kunden schnellere Ergebnisse. KI und HPC-Workloads
Lesen Sie die Erfolgsgeschichte

3000 W AMD Epyc Server-Demontage, mit Wendell von Level1Techs
Wir suchen einen Server, der für Folgendes optimiert ist: KI und maschinellem Lernen. Supermicro hat viel Arbeit investiert, um so viel wie möglich in den 2114GT-DNR (2U2N) – einen Server mit optimierter Dichte – zu packen. Das ist eine wirklich coole Konstruktion: In diesem 2U-Gehäuse sind zwei Systeme untergebracht. Die beiden redundanten Netzteile haben jeweils 2.600 W Leistung, und wir werden sehen, warum wir so viel Strom benötigen. Er beherbergt sechs AMD MI210 Instinct GPUs und die duale Epyc Prozessoren. Sehen Sie sich das hohe Entwicklungsniveau an. Supermicro wurde in das Design dieses Servers integriert.



NEC-Fortschritte KI Forschung mit fortschrittlichen GPU-Systemen von Supermicro
Lesen Sie die Erfolgsgeschichte
Supermicro TECHTalk: Hohe Dichte KI Trainings-/Deep-Learning-Server

Hybride 2U2N-GPU-Workstation-Server-Plattform Supermicro SYS-210GP-DNR Praxis-Test
Heute beenden wir unsere neueste Serie mit einem Blick auf die Supermicro SYS-210GP-DNR, ein 2U-System mit 2 Knoten und 6 GPUs, mit dem Patrick kürzlich einige praktische Erfahrungen sammeln konnte. Supermicro Hauptsitz.

Supermicro SYS-220GQ-TNAR+ ein NVIDIA Redstone 2U Server
Heute schauen wir uns das an Supermicro SYS-220GQ-TNAR+, mit dem Patrick kürzlich einige praktische Erfahrungen sammeln konnte bei Supermicro Hauptsitz.

Enthüllung eines Designsprungs im GPU-System – Supermicro SC21 TECHTalk mit IDC


Maximierung KI Entwicklung und Bereitstellung mit virtualisierten NVIDIA A100 GPUs
Lesen Sie die Lösungsübersicht
Supermicro SuperMinute: 2U 2-Knoten-Server

SuperMinute: 4U-System mit HGX A100 8-GPU

SuperMinute: 2U-System mit HGX A100 4-GPU

Hochleistungsfähige GPU-beschleunigte Virtual-Desktop-Infrastrukturlösungen mit Supermicro Ultra SuperServers
Lesen Sie das Weißbuch
