Supermicro Datenverarbeitungslösungen
Künstliche Intelligenz ermöglichen und Erkenntnisse aus Daten gewinnen
Supermicro Lösungen zur Entwicklung künstlicher Intelligenz mit Daten
Die Herausforderung der Datennutzung bewältigen KI
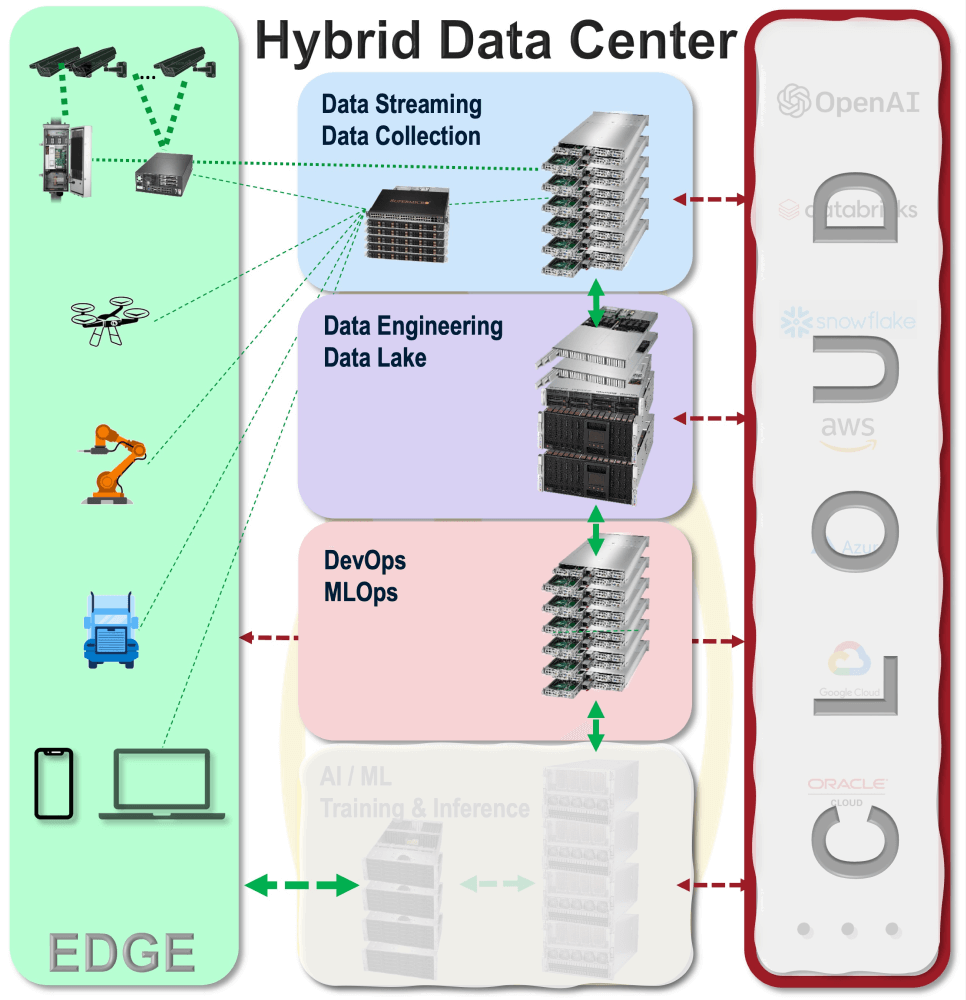
KI Training und Inferenz auf Basis neuer Daten sind entscheidend für die Entwicklung neuer Kundenservices und die Optimierung von Geschäftsabläufen. Dank kostengünstiger Sensoren und zunehmender sozialer Interaktionen mit Kunden über das Internet können Unternehmen die steigenden täglichen Datenmengen erheblich nutzen, um ihre Prozesse zu verbessern. KI Systeme. Implementierung von Datenflusssystemen, die die Privatsphäre der Kundendaten respektieren, unterstützen die folgenden Schlüsselfunktionen. KI Training und Inferenz:
- Datenstreaming zur Verwaltung der Datenerfassung von Edge-Geräten und dem Internet
- Datenstrom zu Systemen, auf denen Apache Kafka, NiFi und Flink laufen
- Datenaufbereitung von Daten aus dem Data Lake, Einrichtung von Datenpipelines für KI Arbeitsabläufe
- Datenpipelines zur Weiterleitung von Daten in verschiedene KI Arbeitsabläufe
- Datenextraktion und -transformation mit Apache Spark
- Data Warehousing mit Apache Hadoop File System (HDFS), Impala, Hive Iceberg und anderen
- DevOps und MLOps zur Steuerung des Workflows in KI Trainings- und Inferenzsysteme
- Kubernetes zur Verwaltung von Containern
- Apache Spark-Graphverarbeitung
Diese Komponenten sind in der Open-Source-Community erhältlich.
Supermicro Cloudera arbeitet mit Cloudera, Open-Source-Anbietern und anderen Softwarepartnern zusammen, um diese Lösungen für Unternehmenskunden bereitzustellen. Cloudera integriert die Softwarekomponenten, die auf der Plattform ausgeführt werden. Supermicro Cloudera bietet Entwicklern und Kunden Software-Support auf Unternehmensebene. Die Softwarekomponenten sind in überschaubare Plattformen und Module für die Bereitstellung gegliedert. Zudem wurden Funktionen zur Datenherkunftssicherung und Datensicherheit hinzugefügt.
Cloudera integriert eine Vielzahl von Open-Source-Software, organisiert diese in einer Plattform, die sowohl lokal als auch in der Cloud betrieben werden kann, und bietet Support auf Unternehmensebene, um Kunden beim Aufbau skalierbarer und zuverlässiger Systeme für Datenerfassung, Datenanalyse, ETL und Data Lakes zu unterstützen. Darüber hinaus hat Cloudera die Datenherkunftsnachverfolgung eingeführt, um die Vertrauenswürdigkeit der Daten zu gewährleisten.
Open-Source-Software wie Apache® Spark™, Kafka, Flink, NiFi, Iceberg, Hadoop und viele weitere fortschrittliche Technologien ermöglichen modernste Softwaresysteme und -architekturen zur Datenerfassung, -analyse, -aufbereitung und -speicherung. Diese Technologien vereinfachen und beschleunigen die Entwicklung künstlicher Intelligenz, indem sie Frameworks zur Organisation und Verwaltung von Daten bereitstellen, um Veränderungen im Zeitverlauf zu bewältigen. Open-Source-Software bietet Zugriff auf die neuesten Technologien; Anwender müssen jedoch ihre Softwareinfrastruktur selbst warten und unterstützen, es sei denn, sie nutzen Softwarelösungen von Anbietern wie Cloudera.

Supermicro Und Cloudera liefert zuverlässige Datenerfassung für KI & Analysen
Lesen Sie die Lösungsübersicht
Supermicro Und Cloudera liefert zuverlässige Datenerfassung für KI & Analysen
Lesen Sie die Lösungsübersicht
Supermicro Cloudera und NVIDIA beschleunigen die Datenanalyse in Unternehmen.
Lesen Sie die Lösungsübersicht
Supermicro A+ Server AS -1124US-TNRP erweitert die OLTP-Leistungsführerschaft mit TPC Benchmark® C (TPC-C®)
Lesen Sie die Lösungsübersicht
Supermicro ATEMPO Datenmigrationslösung für unstrukturierte Daten
Lesen Sie die Lösungsübersicht
Supermicro 2U 4-Knoten TwinPro² Referenzarchitektur für EsgynDB®
Lesen Sie die Erfolgsgeschichte