
NVIDIA GB300 NVL72
Liquid Cooled Rack-Scale Solution with 72 NVIDIA B300 GPUs and 36 Grace CPUs
- GPU: 72 NVIDIA B300 GPUs via NVIDIA Grace Blackwell Superchips
- CPU: 36 NVIDIA Grace CPUs via NVIDIA Grace Blackwell Superchips
- Memory: Up to 21 TB HBM3e (GPU Memory), Up to 17 TB LPDDR5X (System Memory)
- Drives: up to 144 E1.S PCIe 5.0 drive bays

Liquid-Cooled Universal GPU Systems
Direct-to-chip liquid-cooled systems for high-density AI infrastructure at scale.
- GPU: NVIDIA HGX B300/B200/H200
- CPU: Intel® Xeon® or AMD EPYC™
- Memory: Up to 32 DIMMs, 9TB
- Drives: Up to 24 Hot-swap U.2 or 2.5" NVMe/SATA drives

Universal GPU Systems
Modular Building Block Design, Future Proof Open-Standards Based Platform in 4U, 5U, 8U, or 10U for Large Scale AI training and HPC Applications
- GPU: NVIDIA HGX B300/B200/H200, AMD Instinct MI350 Series and MI325X/MI300X/MI250 OAM Accelerator, Intel Data Center GPU Max Series
- CPU: Intel® Xeon® or AMD EPYC™
- Memory: Up to 32 DIMMs, 9TB
- Drives: Up to 24 Hot-swap E1.S, U.2 or 2.5" NVMe/SATA drives

3U/4U/5U GPU Lines with PCIe 5.0
Maximum Acceleration and Flexibility for AI, Deep Learning and HPC Applications
- GPU: Up to 10 NVIDIA H100 PCIe GPUs, or up to 10 double-width PCIe GPUs
- CPU: Intel® Xeon® or AMD EPYC™
- Memory: Up to 32 DIMMs, 9TB or 12TB
- Drives: Up to 24 Hot-swap 2.5" SATA/SAS/NVMe

NVIDIA MGX™ Systems
Modular Building Block Platform Supporting Today's and Future GPUs, CPUs, and DPUs
- GPU: Up to 4 NVIDIA PCIe GPUs including NVIDIA RTX PRO™ 6000 Blackwell Server Edition, H200 NVL, H100 NVL, and L40S
- CPU: NVIDIA GH200 Grace Hopper™ Superchip, Grace™ CPU Superchip, or Intel® Xeon®
- Memory: Up to 960GB ingegrated LPDDR5X memory (Grace Hopper or Grace CPU Superchip) or 16 DIMMs, up to 4TB DRAM (Intel)
- Drives: Up to 8 E1.S + 4 M.2 drives

AMD APU Systems
Multi-processor system combining CPU and GPU, Designed for the Convergence of AI and HPC
- GPU: 4 AMD Instinct MI300A Accelerated Processing Unit (APU)
- CPU: AMD Instinct™ MI300A Accelerated Processing Unit (APU)
- Memory: Up to 512GB integrated HBM3 memory (4x 128GB)
- Drives: Up to 8 2.5" NVMe or Optional 24 2.5" SATA/SAS via storage add-on card + 2 M.2 drives

4U GPU Lines with PCIe 4.0
Flexible Design for AI and Graphically Intensive Workloads, Supporting Up to 10 GPUs
- GPU: NVIDIA HGX A100 8-GPU with NVLink, or up to 10 double-width PCIe GPUs
- CPU: Intel® Xeon® or AMD EPYC™
- Memory: Up to 32 DIMMs, 8TB DRAM or 12TB DRAM + PMem
- Drives: Up to 24 Hot-swap 2.5" SATA/SAS/NVMe

2U 2-Node Multi-GPU with PCIe 4.0
Dense and Resource-saving Multi-GPU Architecture for Cloud-Scale Data Center Applications
- GPU: Up to 3 double-width PCIe GPUs per node
- CPU: Intel® Xeon® or AMD EPYC™
- Memory: Up to 8 DIMMs, 2TB per node
- Drives: Up to 2 front hot-swap 2.5” U.2 per node

GPU Workstation
Flexible Solution for AI/Deep Learning Practitioners and High-end Graphics Professionals
- GPU: Up to 4 double-width PCIe GPUs
- CPU: Intel® Xeon®
- Memory: Up to 16 DIMMs, 6TB
- Drives: Up to 8 hot-swap 2.5” SATA/NVMe
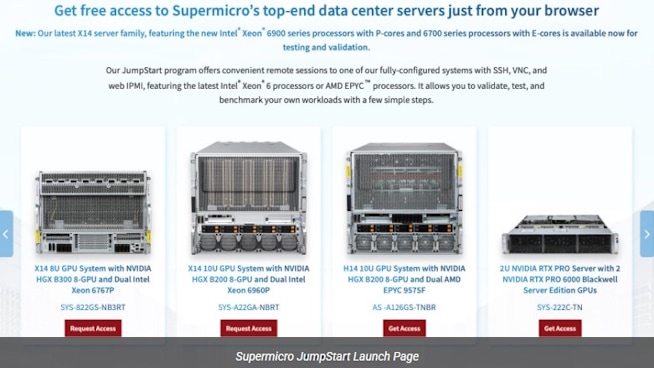
Supermicro JumpStart レビュー:NVIDIA HGX B200を1週間使ってみた
SupermicroのJumpStart このプログラムは、ハードウェア評価に対して非常に異なるアプローチを採用しています。共有ラボ環境での短いスクリプト化されたデモの代わりに、 JumpStart 対象となるお客様には、実際の運用サーバーのカタログへの無料かつ期間限定のベアメタルアクセスを提供します。

Securing AI Workloads with Intel® TDX, NVIDIA Confidential Computing and Supermicro Servers with NVIDIA HGX™ B200 GPUs: A Foundation for Confidential AI at Scale
ホワイトペーパーを読む

Supermicro NVIDIA H200 8-GPU 空冷AIサーバー
今日は、大規模AIサーバーについて引き続き見ていきます。 Supermicro SYS-821GE-TNHR。人々が議論するときSupermicro AIサーバーの性能において、これは空冷式のNVIDIAサーバーとして市場で異彩を放つシステムの1つです。






Supermicro 4U AMD EPYC GPU サーバーがAIに柔軟性を提供(AS-4125GS-TNRT)
Supermicro は、このレビューで取り上げるには時間が足りないほど多くの形状とサイズのGPUサーバーを長年提供してきました。今回は、2つのGPUをサポートする、比較的新しい4U空冷GPUサーバーを見ていきます。 AMD EPYC 9004シリーズCPU、 PCIe Gen5に加え、8枚のダブル幅GPUカードまたは12枚のシングル幅GPUカードを選択可能。


液冷 Supermicro NVIDIA H100 8-GPU AIサーバー SYS-821GE-TNHR のレビュー
今日は液冷式について見ていきたいと思いますSupermicro SYS-821GE-TNHR サーバー。これはSupermicro NVIDIA H100を8基搭載したシステムですが、冷却コストと消費電力を抑えるために液冷式を採用しています。写真があったので、記事にすることにしました。





3000W AMD EPYC サーバーの分解レポート:Level1Techs Wendell氏
私たちは、AIと機械学習に最適化されたサーバーを探しています。 Supermicro は、密度最適化サーバーである2114GT-DNR(2U2N)にできるだけ多くの機能を詰め込むために多くの努力を重ねてきました。これは本当に素晴らしい構造です。この2Uシャーシには2つのシステムが搭載されています。2つの冗長電源はそれぞれ2,600Wで、なぜこれほど多くの電力が必要なのかは後ほど説明します。6つのAMD MI210 Instinct GPUとデュアルEpyc プロセッサ。エンジニアリングのレベルをご覧ください。 Supermicro このサーバーの設計に組み込んだ。




Supermicro TECHTalk:高密度AIトレーニングディープラーニングサーバー

ハイブリッド 2U2N GPUワークステーション&サーバープラットフォームSupermicro SYS-210GP-DNR の製品レビュー
今日は、最新シリーズの締めくくりとして、 Supermicro SYS-210GP-DNRは、2U、2ノード、6GPUシステムで、パトリックは最近、 Supermicro 本部。

Supermicro SYS-220GQ-TNAR+ 2U NVIDIA HGX 4-GPU サーバー
今日は、 Supermicro パトリックが最近実際に触ってみたSYS-220GQ-TNAR+はSupermicro 本部。

GPUシステム設計の飛躍的進歩を発表 - Supermicro SC21 TECHTalk with IDC



SuperMinute:2U 2ノードサーバー

SuperMinute:HGX A100 8GPU搭載4Uシステム

SuperMinute:HGX A100 4GPU搭載2Uシステム


