Supermicro データエンジニアリングソリューション
人工知能の活用とデータからの洞察の生成
Supermicro データを用いて人工知能を設計するためのソリューション
AIにおけるデータ課題への取り組み
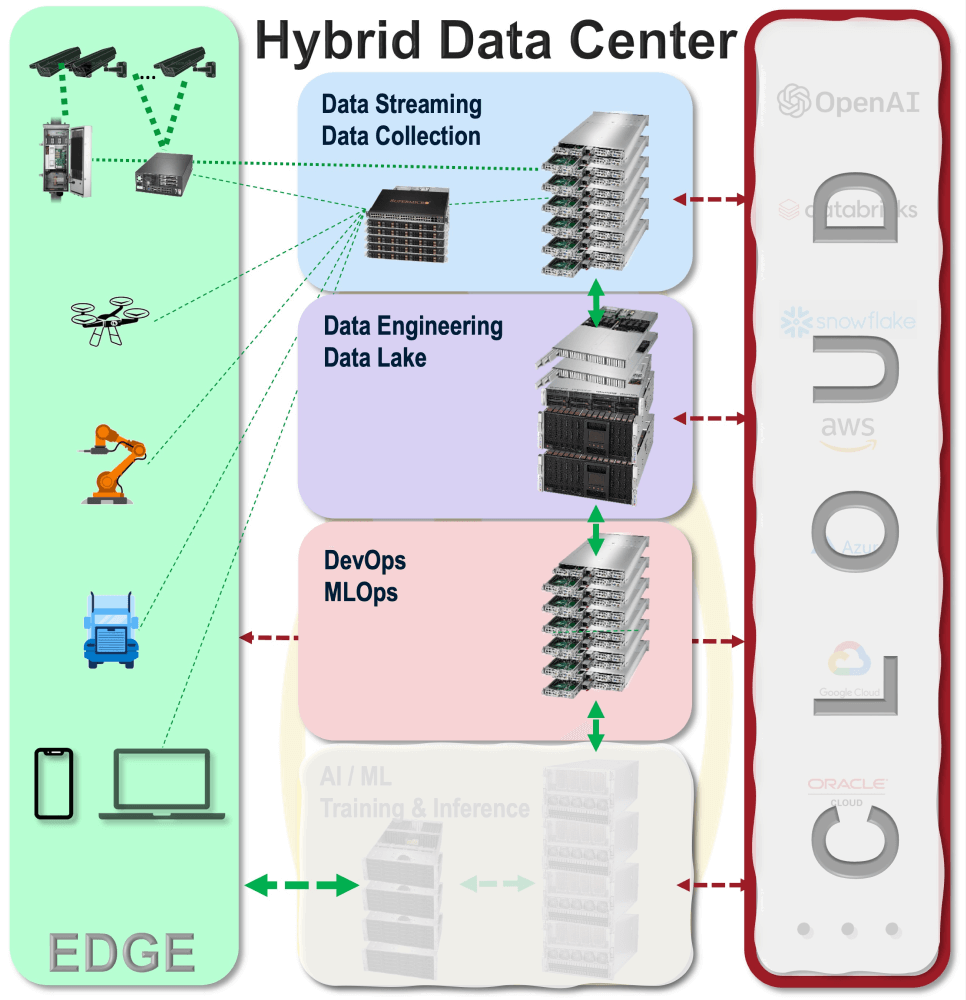
AIトレーニング そして推論 新しいデータを活用することは、顧客への新しいサービスを生み出し、事業運営を最適化する上で重要です。低コストのセンサーとインターネットを介した顧客とのソーシャルインタラクションの増加により、企業は日々増加するデータ量を活用してAIシステムを改善できます。顧客データのプライバシーを尊重するデータフローシステムの実装において、AIをサポートする以下の主要機能が重要です。トレーニング そして推論:
- エッジデバイスとインターネットからのデータ収集を管理するためのデータストリーミング
- Apache Kafka、NiFi、Flinkを実行しているシステムへのデータストリーム
- データレイクから抽出したデータに対するデータエンジニアリング、AIワークフローのためのデータパイプラインの構築
- さまざまなAIワークフローにデータを振り分けるためのデータパイプライン
- Apache Sparkを使用したデータ抽出と変換
- Apache Hadoop File System (HDFS)、Impala、Hive Icebergなどを使用したデータウェアハウジング
- DevOpsとMLOpsがAIにおけるワークフローを推進トレーニング そして推論 システム
- コンテナ管理にはKubernetesを使用する
- Apache Sparkグラフ処理
これらのコンポーネントはオープンソースコミュニティから入手可能です。
Supermicro Clouderaと提携し、オープン出典Clouderaは、他のソフトウェアパートナーとともに、これらのソリューションをエンタープライズ顧客に提供します。 Supermicro Clouderaは、システムを構築し、開発者と顧客に対してエンタープライズレベルのソフトウェアサポートを提供しています。Clouderaは、ソフトウェアコンポーネントを管理しやすいプラットフォームとモジュールに整理し、展開を容易にするとともに、データ来歴情報とデータセキュリティ機能を追加しています。
Clouderaは、膨大な数のオープンソースを統合しています。出典 ソフトウェアは、オンプレミスとクラウドまた、顧客が拡張性と信頼性を備えたデータ収集、データ分析、ETL、データレイクハウスシステムを構築できるよう、エンタープライズレベルのサポートを提供します。さらに、Clouderaはデータの信頼性を確保するためにデータプロベナンス機能を追加しました。
Apache® Spark™、Kafka、Flink、Nifi、Iceberg、Hadoopなどのオープンソースソフトウェアの進歩により、データの収集、分析、エンジニアリング、保存を行う最新のソフトウェアシステムとアーキテクチャが実現しました。これらのテクノロジーは、時間の経過に伴う変化に対応するためにデータを整理および管理するフレームワークを提供することで、人工知能を簡素化し、高速化します。出典 ソフトウェアは最新技術を提供するが、Clouderaのような企業が提供するソフトウェアを使用しない限り、ユーザーは自身のソフトウェアインフラストラクチャを維持・サポートする必要がある。




Supermicro A+ Server AS-1124US-TNRPは、TPC Benchmark® C(TPC-C®)によりOLTPパフォーマンスにおけるリーダーシップをさらに強化します。
ソリューション概要を読む

