Supermicro エンジニアリングソリューション
人工知能の実現とデータからの洞察の創出
データを活用した人工知能の構築に向けたSupermicro
AIのためのデータ・チャレンジ
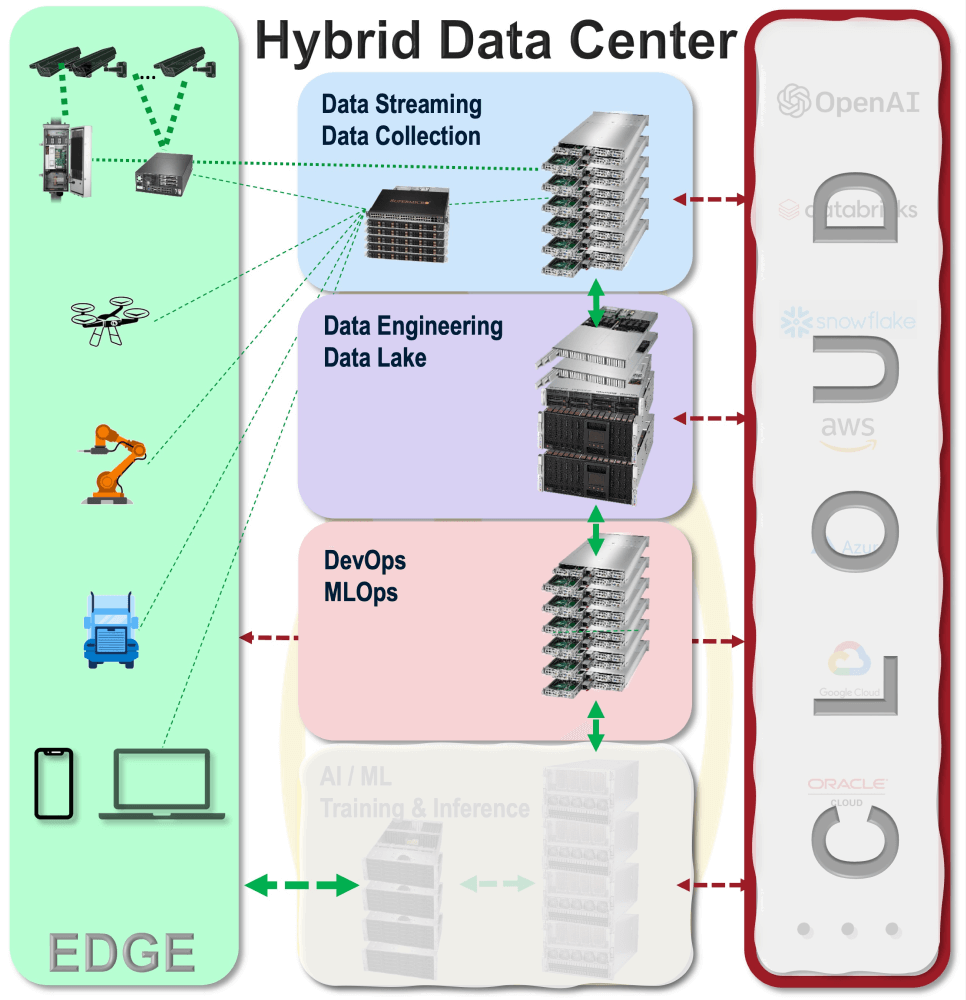
新しい推論 トレーニング 推論 、顧客向けの新たなサービスを創出したり、業務運営を最適化したりするための鍵となります。低コストのセンサーや、インターネットを通じた顧客との交流の増加により、企業は日々増加するデータを活用してAIシステムを改善し、大きなメリットを得ることができます。顧客データのプライバシーを尊重したデータフローシステムを導入することで、以下の主要な機能がトレーニング 推論を支えます:
- エッジデバイスやインターネットからのデータ収集を管理するデータストリーミング
- Apache Kafka、NiFi、Flinkを実行するシステムへのデータストリーム
- データレイクから抽出したデータのデータエンジニアリング、AIワークフローのためのデータパイプラインの設定
- データをさまざまなAIワークフローに導くデータパイプライン
- Apache Sparkを使用したデータ抽出と変換
- Apache Hadoop File System (HDFS)、Impala、Hive Icebergなどを使用したデータウェアハウジング
- AIトレーニング 推論 におけるワークフローを推進するDevOpsとMLOps
- コンテナを管理するKubernetes
- Apache Sparkグラフ処理
これらのコンポーネントは、オープンソースコミュニティから入手可能です。
Supermicro 、Clouderaやオープンソース、その他のソフトウェアパートナーとSupermicro 、これらのソリューションを企業のお客様に提供しています。Clouderaは、Supermicro 動作するようソフトウェアコンポーネントを統合し、開発者やお客様に対してエンタープライズレベルのソフトウェアサポートを提供しています。Clouderaは、ソフトウェアコンポーネントを管理しやすいプラットフォームやモジュールに整理して展開できるようにするとともに、データの出所追跡機能やデータセキュリティ機能も追加しています。
Clouderaは、膨大なオープンソースソフトウェアを統合し、クラウド動作するプラットフォームとして体系化しています。また、エンタープライズレベルのサポートを提供し、お客様がスケーラブルで信頼性の高いデータ収集、データ分析、ETL、およびデータレイクハウスシステムを構築できるよう支援しています。さらに、Clouderaはデータの信頼性を確保するために、データの出所追跡機能を追加しました
Apache® Spark™、Kafka、Flink、Nifi、Iceberg、Hadoopなどのオープンソースソフトウェアは、データの収集、データの分析、データのエンジニアリング、データの保存を行う最新のソフトウェアシステムとアーキテクチャを提供します。これらのテクノロジーは、時間の経過に伴う変化に対応するためにデータを整理・管理するフレームワークを提供することで、人工知能を簡素化・迅速化します。オープンソースソフトウェアは最新のテクノロジーを提供しますが、Clouderaのような企業によって組織されたソフトウェアを使用しない限り、ユーザーはソフトウェアインフラを維持しサポートする必要があります。




Supermicro Server AS-1124US-TNRP、TPC Benchmark® C (TPC-C®) においてOLTPパフォーマンスのトップクラスを維持
ソリューション概要を読む

